Awarie serwerów są nieodłącznym elementem eksploatacji infrastruktury IT, bez względu na to, czy mówimy o sprzęcie od HP (HPE), Dell, IBM, czy SuperMicro.
Choć każdy z producentów stosuje nieco inne rozwiązania w zakresie konstrukcji serwerów, oprogramowania układowego czy zarządzania zdalnego, finalnie skutki awarii mogą być podobne: niedostępność systemów, ryzyko utraty danych, a nawet groźba poważnego przestoju w działalności firmy.
W niniejszym artykule przyjrzymy się głównym przyczynom awarii serwerów od wiodących producentów, przeanalizujemy wpływ tych awarii na bezpieczeństwo danych, a także wskażemy metody zapobiegania i skuteczne procedury odzyskiwania danych po ewentualnej usterce.
Rodzaje i przyczyny awarii serwerów
1.1 Awarie sprzętowe
-
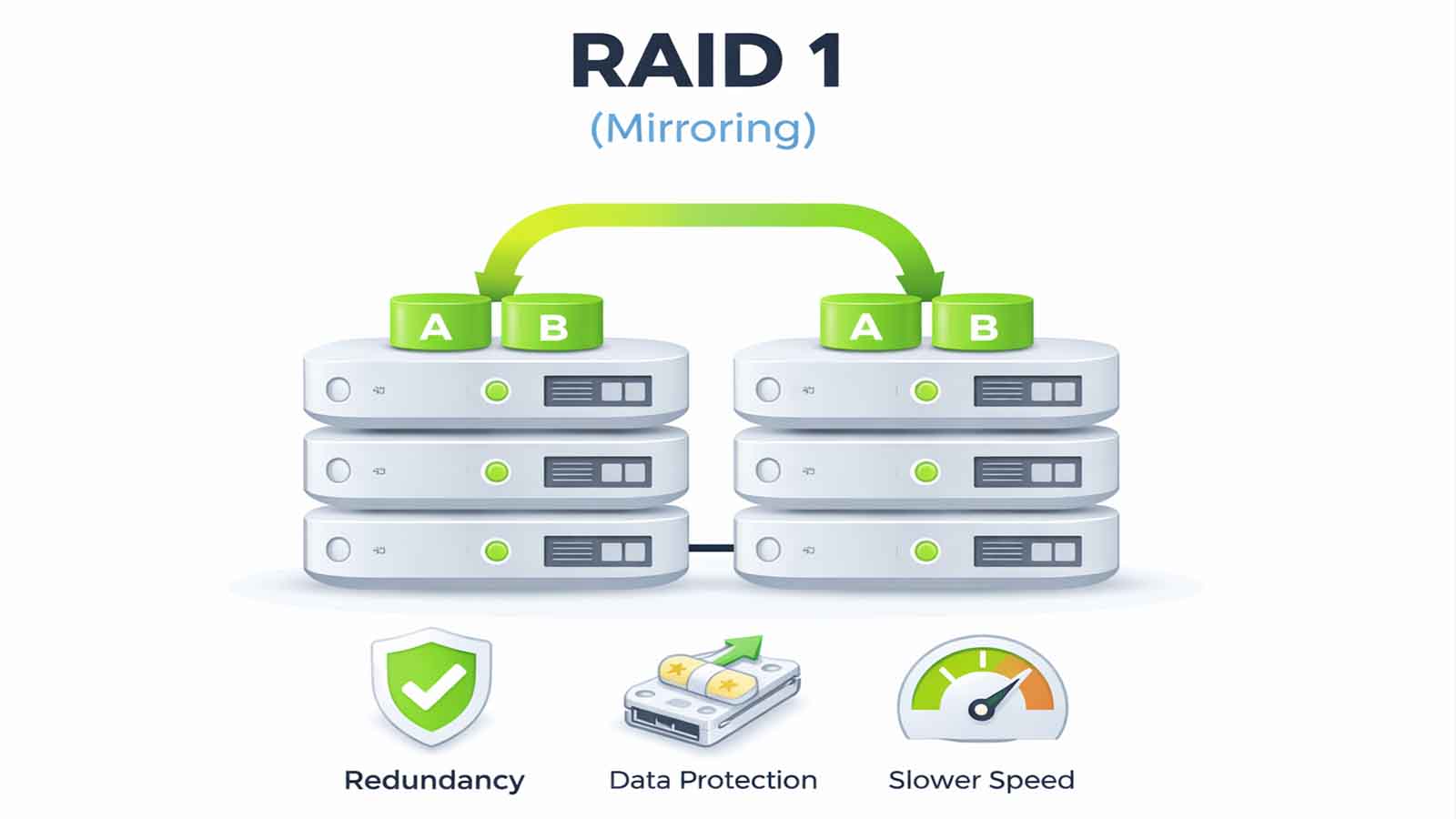
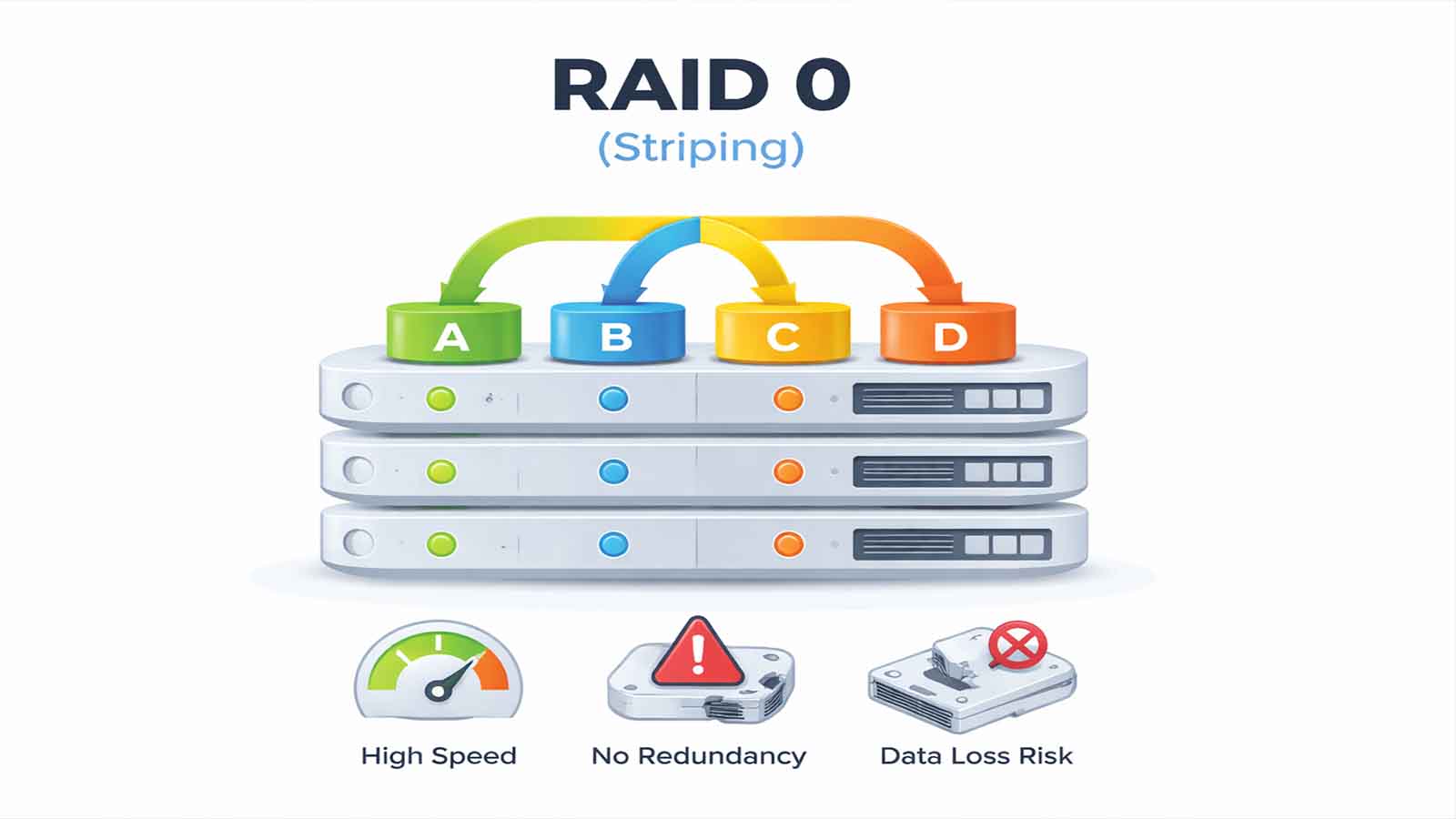
Dyski twarde i macierze RAID
Dyski twarde (HDD i SSD) w serwerach, niezależnie od producenta sprzętu, mogą ulegać zużyciu. Na awaryjność duży wpływ ma intensywność zapisu/odczytu, temperatura pracy, a także wstrząsy czy wibracje. Konfiguracje RAID (zwłaszcza RAID 5 lub RAID 6) zapewniają redundancję, ale nie eliminują całkowicie ryzyka utraty danych.- Przykładowo: kontrolery RAID w serwerach HPE (Smart Array), Dell (PERC), IBM/Lenovo (ServeRAID) czy SuperMicro (dowolne kontrolery, często Avago/Broadcom/LSI) – mimo różnic w nazwie i funkcjonalnościach – mogą ulegać podobnym awariom sprzętowym i firmware’owym.
-
Pamięć RAM
Pamięci ECC (Error-Correcting Code) stosowane w serwerach mają za zadanie wykrywać i korygować drobne błędy, ale nie zawsze zapobiegają poważnym uszkodzeniom modułów. W przypadku uszkodzenia lub niekompatybilności pamięci serwer może się resetować, zawieszać lub generować błędy zapisu danych. -
Zasilacze (PSU)
Wszystkie serwery klasy enterprise (HP, Dell, IBM, SuperMicro) oferują zwykle nadmiarowe zasilacze (redundantne PSU). Mimo tego uszkodzenia mogą wystąpić podczas przepięć, wahań napięcia lub przy przegrzaniu. Problemy z zasilaniem często eskalują i prowadzą do nagłego wyłączenia serwera, co może skutkować uszkodzeniem macierzy RAID czy systemu plików. -
Płyta główna i kontrolery
Każdy producent stosuje swoje rozwiązania w zakresie płyt głównych i zintegrowanych kontrolerów (zarówno sieciowych, jak i peryferyjnych). Usterka w obwodzie zintegrowanego układu (np. chipsetu) może spowodować niestabilność serwera, a w konsekwencji utratę danych.
1.2 Awarie oprogramowania układowego (firmware) i BIOS/UEFI
Wraz z rozwojem technologii producenci serwerów regularnie wypuszczają aktualizacje BIOS/UEFI, sterowników i firmware kontrolerów RAID, a także modułów zarządzających (np. iLO w HP, iDRAC w Dell, IMM w IBM, IPMI w SuperMicro).
- Nieudana aktualizacja może doprowadzić do braku możliwości uruchomienia serwera lub do niepoprawnego działania systemu, co z kolei może skutkować błędami zapisu i odczytu danych.
- Niekompatybilność wersji firmware poszczególnych podzespołów w serwerze może generować konflikty i prowadzić do awarii lub niestabilności systemu.
1.3 Problemy z systemem operacyjnym i aplikacjami
Czasami przyczyny awarii serwera nie leżą stricte w sprzęcie, lecz w błędach systemu operacyjnego (np. Windows Server, Linux) czy uruchamianych aplikacji (serwery baz danych, serwery wirtualizacyjne, itp.). Źle zaprogramowana aplikacja lub konflikt w sterownikach może „zawiesić” serwer i narazić dane na uszkodzenie.
1.4 Błędy ludzkie
- Nieprawidłowa konfiguracja RAID
- Źle dobrane parametry BIOS/UEFI
- Niewłaściwa obsługa hot-swap (wyjęcie dysku nie tego, co trzeba)
- Brak aktualnych kopii zapasowych
Często ludzki czynnik jest główną przyczyną poważnej awarii, zwłaszcza gdy naruszane są procedury bezpieczeństwa lub brakuje regularnego nadzoru nad serwerem.
Specyfika awarii w serwerach HP, Dell, IBM i SuperMicro
Choć zasada działania serwerów od tych producentów jest podobna, to jednak pewne różnice w architekturze i dostępnych funkcjach mogą wpływać na rodzaj i przebieg awarii.
-
HP (HPE)
- iLO (Integrated Lights-Out) – zaawansowane narzędzie do zdalnego zarządzania. Czasem problemy z jego firmware mogą spowodować zawieszenie całego systemu lub trudności w diagnostyce.
- Smart Array – kontrolery RAID charakteryzują się własnymi funkcjami (np. cache, akceleracja zapisu). Awaria baterii podtrzymującej pamięć cache może skutkować utratą danych buforowanych przed zapisem na dysk.
-
Dell
- iDRAC (Integrated Dell Remote Access Controller) – podobnie jak iLO, zarządza serwerem zdalnie. Nieprawidłowo przeprowadzona aktualizacja iDRAC może zablokować start serwera lub prowadzić do błędnej konfiguracji RAID.
- PERC RAID – kontrolery RAID Dell (PERC) oparte na chipsetach Broadcom/LSI. Błędy firmware lub braki w obsłudze poszczególnych trybów RAID (np. pass-through) mogą utrudnić odzyskiwanie danych.
-
IBM (obecnie często w kontekście Lenovo System x)
- IMM (Integrated Management Module) – moduł odpowiedzialny za zdalne zarządzanie, narażony na podobne problemy jak iLO/iDRAC.
- ServeRAID – autorskie kontrolery IBM/Lenovo, choć również bazują często na układach LSI/Broadcom.
- IBM/Lenovo mają w ofercie zaawansowane rozwiązania pamięci masowych, a awarie mogą obejmować zarówno serwery x86, jak i maszyny Power Systems.
-
SuperMicro
- Zwykle wykorzystuje IPMI (Intelligent Platform Management Interface) do zdalnego zarządzania.
- Serwery SuperMicro są często cenione za elastyczność konfiguracyjną (dużo możliwych wariantów płyt głównych i obudów). Jednak różnice w jakości poszczególnych komponentów (zależnie od dostawcy) mogą powodować większą zmienność w rodzaju usterek.
- Kontrolery RAID często są dokupywane jako osobne karty (LSI, Broadcom), co wymaga szczególnej uwagi przy doborze sterowników i firmware.
Wpływ awarii na bezpieczeństwo danych
-
Przerwa w dostępności
Najbardziej bezpośredni skutek awarii to niedostępność danych i usług. Dla wielu przedsiębiorstw godziny przestoju mogą generować wysokie koszty i utratę reputacji. -
Ryzyko nieodwracalnej utraty danych
W przypadku uszkodzenia struktur macierzy RAID, tablic partycji czy systemu plików istnieje ryzyko, że dane zostaną utracone na stałe. Dotyczy to szczególnie sytuacji, gdy awarii ulegają dwa lub więcej dysków w RAID 5/6, albo gdy brakuje aktualnych kopii zapasowych. -
Ujawnienie informacji
Czasem awaria może prowadzić do błędów w kontrolerze lub systemie plików, co umożliwia odczyt części danych przez nieuprawnione procesy. Dodatkowo, jeśli w procesie naprawy konieczne jest zaangażowanie zewnętrznej firmy, istnieje ryzyko ujawnienia wrażliwych danych (np. osobom trzecim). -
Wpływ na polityki RODO/GDPR
Jeśli serwer przechowuje dane osobowe, każda niekontrolowana awaria i potencjalny wyciek danych może wymagać zgłoszenia incydentu do odpowiednich organów nadzorczych.
Jak się zabezpieczyć przed awariami?
-
Redundancja i wysokodostępność (High Availability)
- Stosowanie macierzy RAID z odpowiednią tolerancją na awarie (RAID 1, 5, 6, 10) w zależności od obciążenia i wymaganej pojemności.
- Korzystanie z klastrów wysokiej dostępności (np. wirtualizacja w środowiskach VMware, Hyper-V czy KVM z replikacją danych).
-
Regularne kopie zapasowe (backup)
- Codzienne lub tygodniowe backupy (pełne, przyrostowe, różnicowe).
- Kopie zapasowe przechowywane w innej lokalizacji (off-site), w chmurze lub w odrębnej sieci.
- Testowanie odzyskiwania danych z kopii (tzw. DR Test – Disaster Recovery Test).
-
Monitorowanie stanu serwera
- Wykorzystanie narzędzi producenta (HPE iLO, Dell iDRAC, IBM IMM, SuperMicro IPMI) do ciągłego nadzoru parametrów serwera (temperatury, stanu dysków, alertów).
- Systemy SIEM lub dedykowane rozwiązania do monitorowania logów (np. Nagios, Zabbix, PRTG).
-
Aktualizacje oprogramowania
- Regularne uaktualnianie BIOS/UEFI, firmware kontrolerów RAID, sterowników i systemu operacyjnego.
- Przed aktualizacją – wykonywanie backupu i sprawdzenie zgodności wersji (dla HP: matryca zgodności SPP, dla Dell: pakiet SUU itp.).
-
Zabezpieczenia fizyczne i środowiskowe
- Zasilanie awaryjne (UPS) i agregaty prądotwórcze.
- Klimatyzacja i utrzymanie odpowiedniej temperatury w serwerowni.
- Ochrona przed pyłem, wibracjami i dostępem osób nieuprawnionych.
-
Procedury i szkolenia
- Dokumentacja i wytyczne dotyczące obsługi serwerów, wymiany dysków w trybie hot-swap, rekonfiguracji RAID.
- Regularne szkolenia zespołu IT, aby minimalizować ryzyko błędu ludzkiego.
Odzyskiwanie danych z serwera
5.1 Wstępna diagnoza i ocena sytuacji
-
Zidentyfikuj przyczynę
- Sprawdź stan diod sygnalizacyjnych na serwerze.
- Zaloguj się do interfejsu zdalnego zarządzania (iLO, iDRAC, IMM, IPMI) i przeanalizuj logi sprzętowe (System Event Log, RAID Controller Logs).
- Upewnij się, czy problem dotyczy dysków, kontrolera RAID, pamięci czy innego komponentu.
-
Nie podejmuj pochopnych działań
- Nie wyjmuj dysków na chybił trafił, jeśli nie wiesz, który faktycznie uległ awarii.
- Nie przeprowadzaj napraw systemu plików (np. fsck, chkdsk) bez upewnienia się, że nie pogorszy to sytuacji.
-
Zweryfikuj backupy
- Jeśli posiadasz kopie zapasowe, sprawdź ich aktualność i możliwość przywrócenia.
- Oceń, czy odtworzenie z backupu nie będzie szybsze i bezpieczniejsze niż próby naprawy uszkodzonej macierzy.
5.2 Procedury naprawy macierzy RAID
-
Wymień uszkodzony dysk (jeśli to konieczne)
- Upewnij się, że dysk zamienny ma co najmniej taką samą pojemność.
- Skontroluj, czy wymiana odbywa się w trybie hot-swap i czy kontroler RAID widzi nowy dysk poprawnie.
- Rozpocznij proces odbudowy macierzy (rebuild). Monitoruj logi, aby wychwycić ewentualne błędy.
-
Napraw lub przywróć konfigurację RAID
- W przypadku uszkodzenia metadanych RAID może być konieczne odtworzenie konfiguracji (np. przez funkcję “Import Foreign Configuration” w PERC Dell, “Rebuild Configuration” w HPE Smart Array).
- Jeśli macierz nie daje się przywrócić, należy rozważyć skorzystanie z profesjonalnych narzędzi do odzyskiwania RAID.
-
Weryfikacja i testy
- Po odbudowie sprawdź spójność systemu plików (w przypadku Linux – e2fsck/xfs_repair, Windows – chkdsk).
- Przeprowadź test odczytu/zapisu, aby upewnić się, że macierz pracuje poprawnie.
5.3 Profesjonalne odzyskiwanie danych
W przypadku poważnych uszkodzeń mechanicznych dysków twardych (np. poważna utrata sektorów, uszkodzenie głowic) lub braku możliwości naprawy logicznej RAID warto rozważyć współpracę z wyspecjalizowanymi laboratoriami odzyskiwania danych.
- Laboratoria dysponują tzw. clean roomami do otwierania dysków bez ryzyka dalszych uszkodzeń.
- Korzystają z zaawansowanych narzędzi umożliwiających rekonstrukcję macierzy RAID na poziomie blokowym.
- Bezpieczeństwo danych – ważne jest podpisanie umów poufności (NDA), aby chronić wrażliwe informacje znajdujące się na nośnikach.
5.4 Przywracanie z kopii zapasowej
Jeśli posiadasz aktualny i sprawdzony backup:
- Zainicjuj nową macierz RAID (albo skorzystaj z serwera zastępczego).
- Zainstaluj system operacyjny.
- Odtwórz dane z kopii zapasowej.
- Zweryfikuj integralność i poprawność odtworzonych danych.
- Upewnij się, że cały system działa tak, jak przed awarią (testy usług, aplikacji, baz danych).
Ciekawy przykład odzyskiwania danych z serwera HP https://www.alldatarecovery.pl/raid/274-zlecenie-odzyskiwanie-danych-z-serwera-hp-proliant
Podsumowanie
Awarie serwerów HP, Dell, IBM czy SuperMicro mogą mieć istotny wpływ na bezpieczeństwo danych oraz ciągłość działania przedsiębiorstwa. Choć każdy z producentów oferuje własne rozwiązania i systemy zarządzania, przyczyny usterek – od problemów sprzętowych (dyski, pamięć, zasilanie) przez błędy firmware, aż po błąd ludzki – pozostają podobne i mogą dotknąć dowolną platformę.
Kluczowe kroki minimalizujące ryzyko:
- Dbanie o redundancję (RAID, klaster HA, zasilacze).
- Regularne kopie zapasowe i testowanie procesu odzysku danych.
- Monitorowanie (iLO, iDRAC, IMM, IPMI) oraz aktualizacje firmware i BIOS.
- Procedury – jasne wytyczne dotyczące wymiany dysków, konfiguracji RAID, zarządzania serwerem.
- Szkolenia personelu IT i testy disaster recovery.
W przypadku faktycznej awarii najważniejsze jest zachowanie spokoju, diagnoza źródła problemu oraz konsekwentne realizowanie kroków naprawczych. Jeśli dane są krytyczne, a uszkodzenia – poważne, należy rozważyć współpracę z profesjonalnym laboratorium odzyskiwania danych. Ostatecznie jednak to dobrze zaprojektowane i przetestowane backupy dają największą gwarancję, że nawet w obliczu najbardziej dotkliwej awarii unikniemy katastrofalnej utraty informacji.